概要 #
物体検出機能は、画像解析AIを用いて物体の有る/無しを検出する機能です。これを用いることで、「何が」「いつ」「どこに」「何個」あるのかをリアルタイムで判定できます。本マニュアルでは、物体検出AIの作成方法をまとめています。
物体検出AI作成フロー #
Loggerで解析動画を取得した後のフローは以下のとおりです。各項目をクリックすると、実施手順の詳細の確認ができます。
事前準備 #
Microsoftパッケージのダウンロード
「Visual C++ 再頒布可能パッケージ」を2つダウンロードする必要があります。
①VC++(2015以降)
以下リンクをクリックして、exeファイルをダウンロード。
実行してパッケージをダウンロードする。
VC++(2015以降)
②VC++(2013)
以下リンクをクリックして、「vcredist_x64.exe」を選択後、exeファイルをダウンロード。
実行してパッケージをダウンロードする
VC++(2013)ダウンロードページ
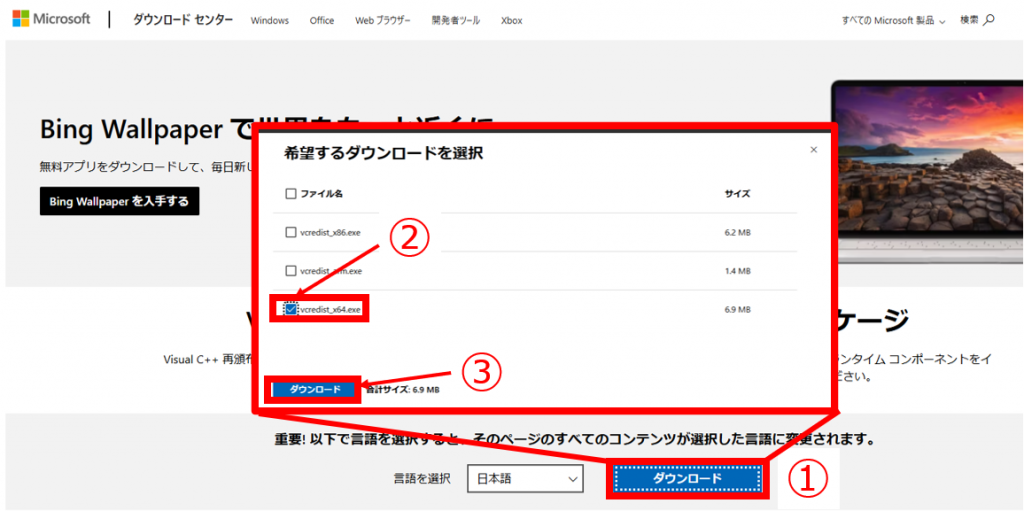
※すでにダウンロード済かどうかは「コントロールパネル>プログラム>プログラムと機能」から確認できます
※①と②は互換性がないため、どちらもダウンロードが必要です
検出対象の決定
AIに検出させたい物体(人)をあらかじめ決定してください。一つのAIモデルで、複数の物体(人)を検出することも可能です。
Logger端末とカメラの設置
Logger端末およびカメラの設置は、Loggerマニュアル「物体検出AIの導入と実装」を参照してください。
Loggerで取得した動画の選定
Loggerで取得した動画から、学習に用いたいものを選定し、Viewer用のPCに保存してください。
動画選定のポイント
動画選定は、学習品質に関わる重要な工程です。以下に留意して動画を選定してください。
・動画内容にバリエーションがあるか
①よくあるパターン
②検出対象の姿勢にバリエーションがあるか(例:ライン内、玉掛け時、組付け時)
③レアケース(始業時・終業時・休憩・夜勤・荒天)
・「検出対象なし」動画も用意する
手順詳細 #
AIモデルの学習プロジェクト作成 #
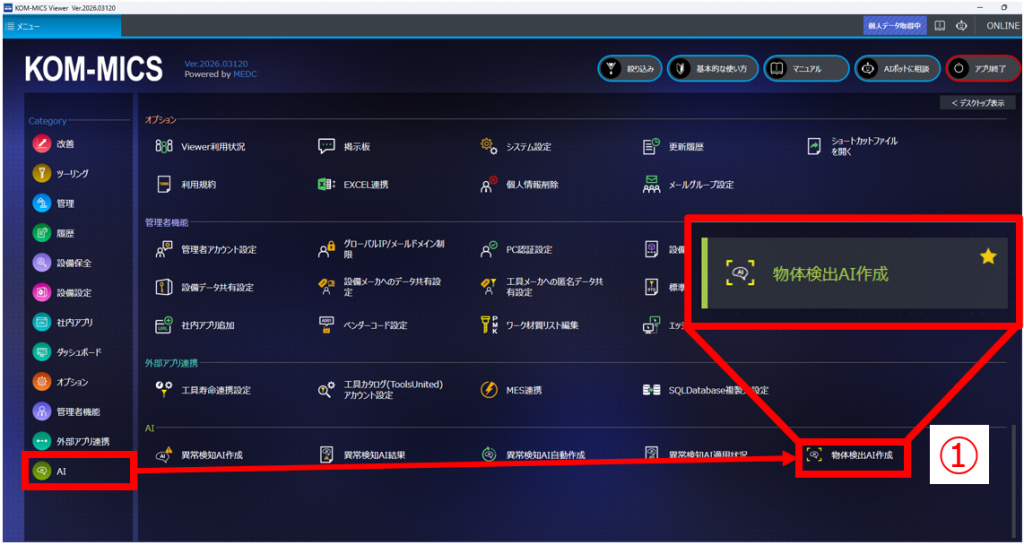
①「AI」カテゴリの「物体検出AI作成」アプリをクリック
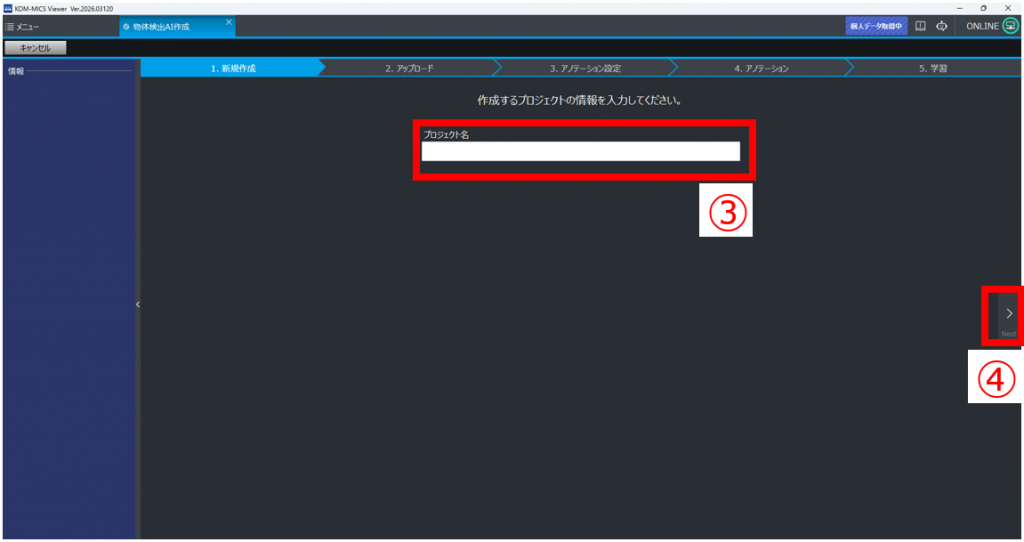
②「新規作成」をクリック
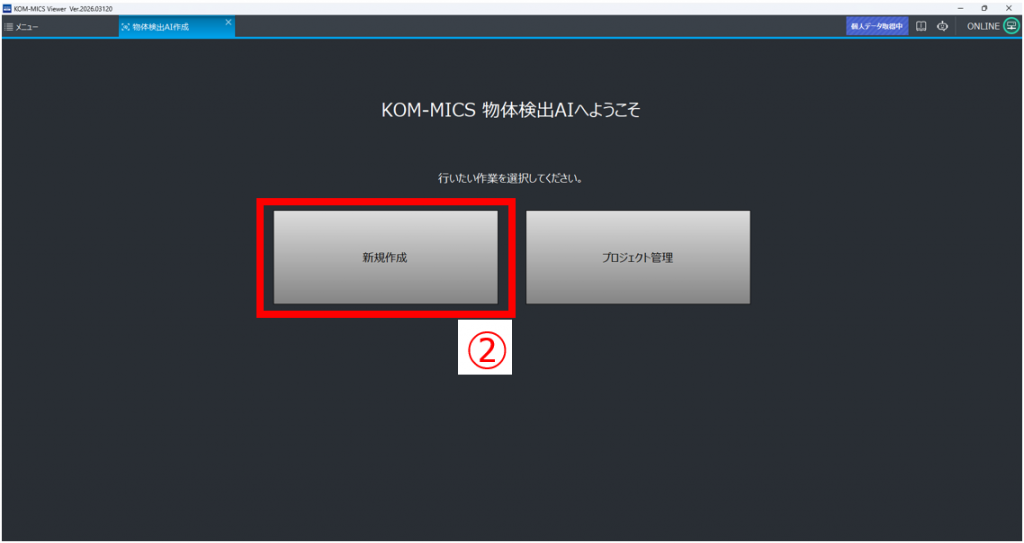
③任意のプロジェクト名を設定
④「Next」をクリック
学習用画像の作成 #
・学習データが「動画(mp4)」の場合
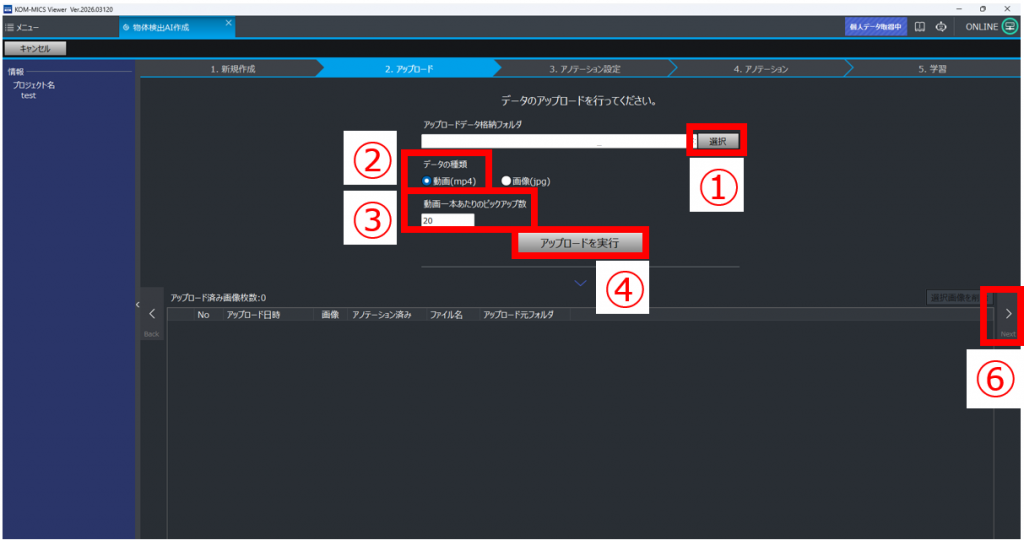
①「選択」をクリックし、取得した動画(mp4)が格納されているフォルダを選択する
②データの種類を「動画(mp4)」にチェックをつける
③「動画1本あたりのピックアップ数」に、動画1本を何枚の静止画に分解するかを入力する
(例:10分の動画 10本を、ピックアップ数=10でアップロード→100枚の静止画)
④「アップロードを実行」をクリック
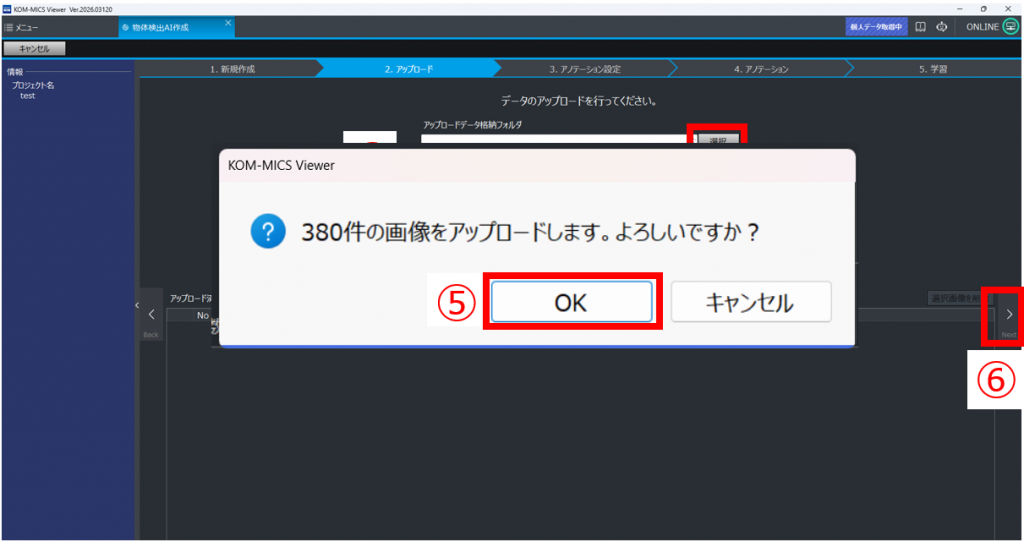
⑤ポップアップの画像枚数を確認し「OK」をクリック
※画像枚数=動画数×ピックアップ数
⑥「Next」をクリック
・学習データが「画像(jpg)」の場合
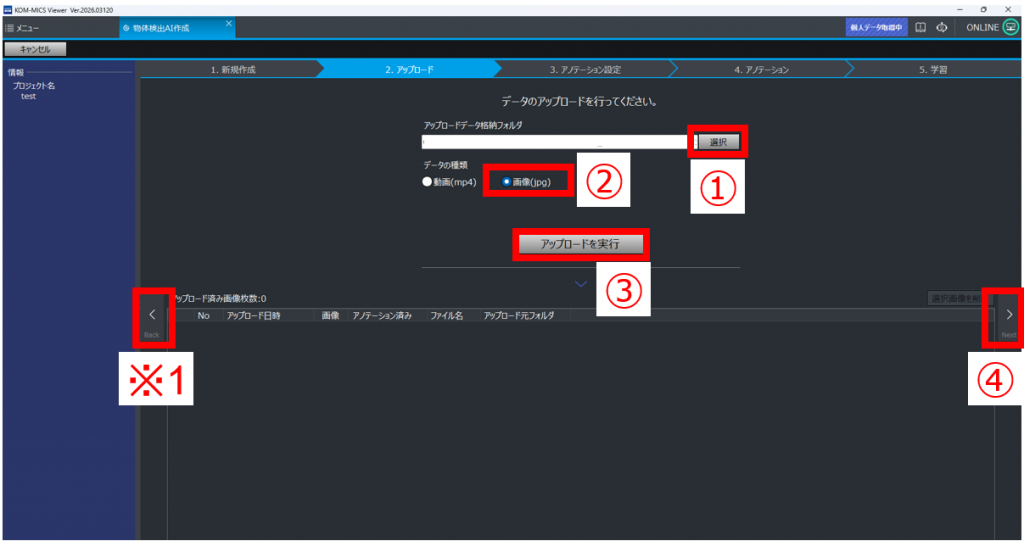
①学習データが「動画」の場合と同様に、フォルダを選択する
②データの種類を「画像(jpg)」にチェックをつける
③「アップロードを実行」をクリック
④「Next」をクリック
(※1)以降、「Back」をクリックすると前の操作に戻れる
タグ付け(アノテーション)設定 #
以降、「何が」「どこにある」の教示を、「アノテーション」と記載する。
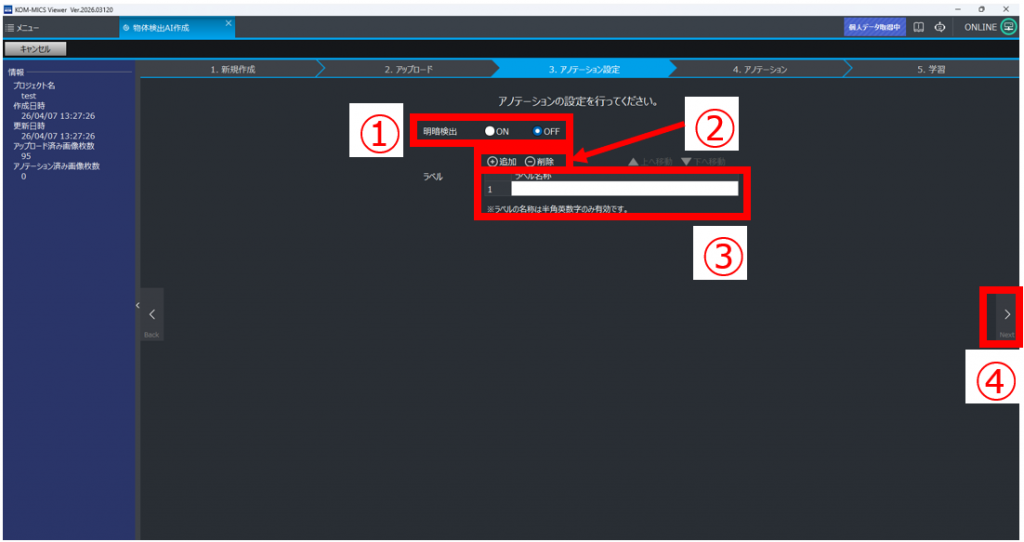
①「明暗検出」を行うか設定する
「明暗検出機能」はこちらを参照
②ラベルの「追加」をクリックしラベルを作成する
作成したラベルを削除したい場合は、ラベルを選択後、「削除」をクリックする
③ラベル名称を設定する(※半角英数字のみ)
名称例)1human
上記のように、ラベル番号を名称に含めると、結果閲覧時にわかりやすい
④「Next」をクリック
アノテーション #
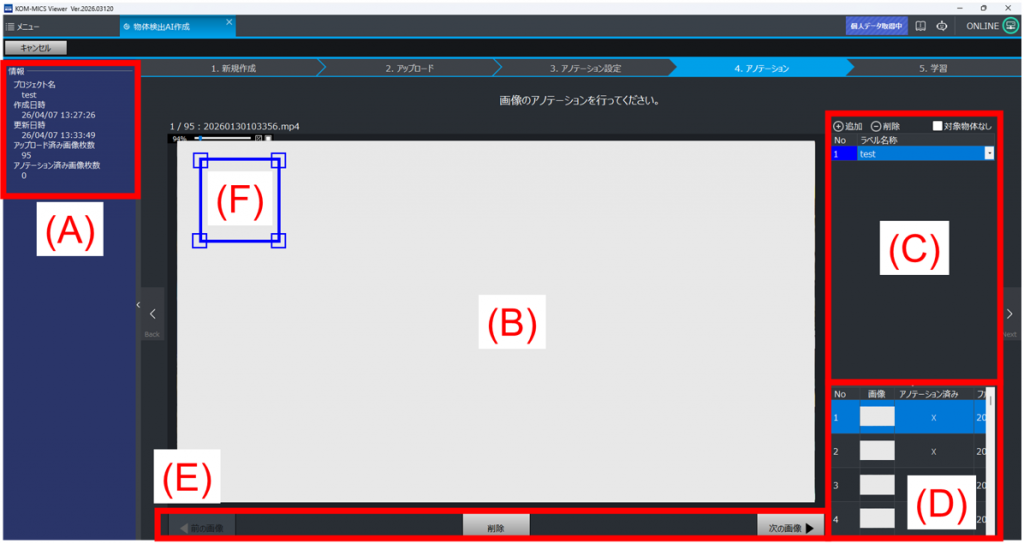
画面構成 #
画面構成は以下のようになっている
(A) プロジェクト情報エリア
(B) 学習画像のアノテーションエリア
(C) アノテーション用ボックス情報・編集エリア
(D) 学習画像一覧
(E) 画像選択バー
(F) アノテーション用ボックス
操作方法 #
①ラベルリストの「追加」、または画像の任意の場所を「ダブルクリック」し、ボックスを画像内に表示する
②ラベルリストの「▼」をクリックし、検出物体のラベルを選択する

③ラベルリストの「ラベル」をクリック、または画像の「ボックス内をクリック」し、ボックスを選択する
④「選択したボックス内にカーソルを合わせ」、「ドラッグ」し検出対象にボックスを移動させる
⑤「ボックスの四隅にカーソルを合わせ」、「ドラッグ」しながら大きさを調節する
ボックスの大きさは、検出物体が収まる程度の大きさにする
※①-⑤を繰り返して、画像内の「すべての検出物体」をアノテーションする
※画像から見切れていても「人が見てその物体であると判断できる場合」はアノテーションして構わない
⑥すべての検出物体にアノテーションができたら、「(D)の次画像」、または「次の画像」をクリックし、次に進む

以降、①ー⑥を各画像に行う。
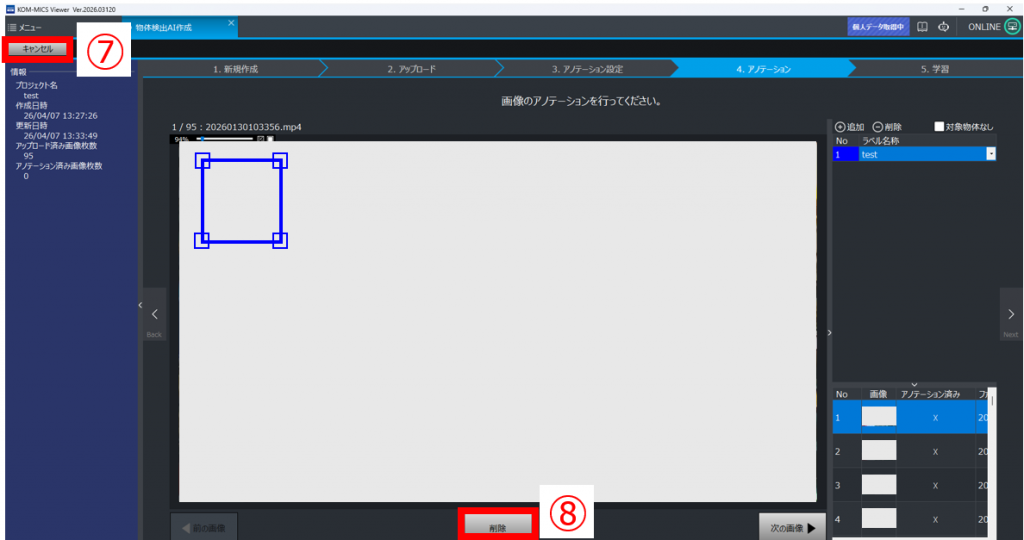
⑦学習画像として必要でない場合、「削除」をクリックし、画像を消去する
⑧「キャンセル」をクリックすると、作業中断できる(作業内容は自動保存)
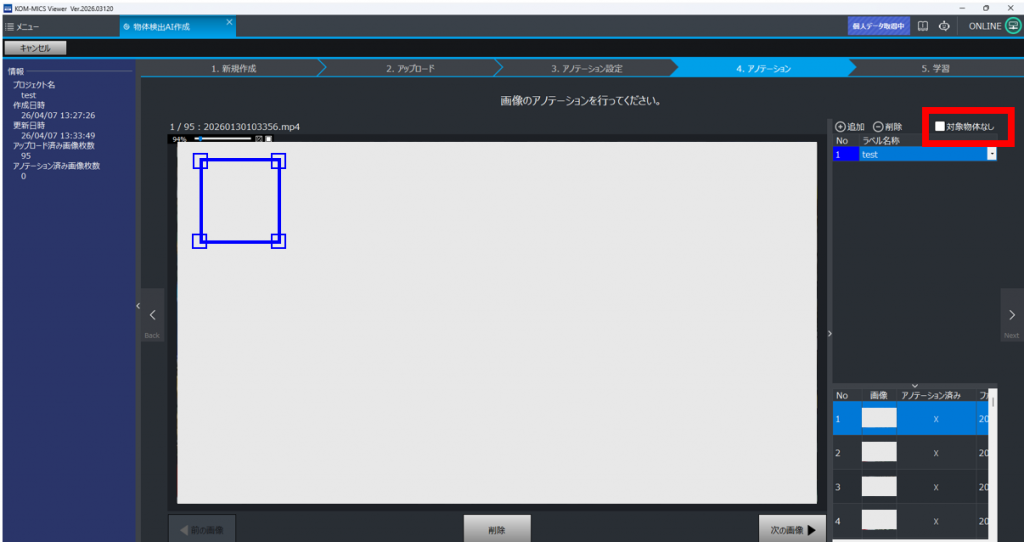
検出物体が画像内にないとき #
ラベルリストの「対象物体なし」をチェックし、次の画像を選択する
明暗検出機能を用いるとき #
明暗検出機能を用いる場合、すべての画像の「明暗検出タグ」をアノテーションする
明暗検出機能はこちらを参照
モデル学習 #
画面構成は以下のようになっている
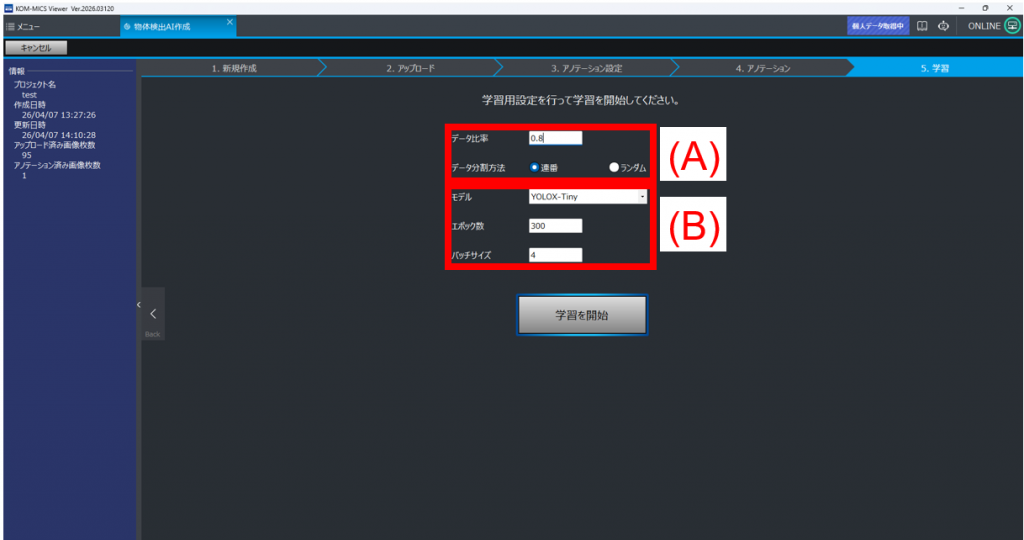
(A) 学習データ設定
・データ比率:学習用と評価用のデータの分割比率
※学習用と評価用のどちらにもデータが含まれていないと「学習失敗」となります
・データ分割方法:データ分割が連番/ランダム
(B) 学習モデル・方法設定
・モデル:Logger端末の場合、YOLOX-Tiny推奨
・エポック数(=学習回数):100~300回程度推奨
・バッチサイズ:一度にどのくらいの情報量をAIに処理させるか
・設定が完了したら、「学習を開始」をクリックし、学習開始する
※基本的には、デフォルト設定で学習を開始して問題ない
※Viewer、PCを閉じても学習は継続される
学習結果の確認 #
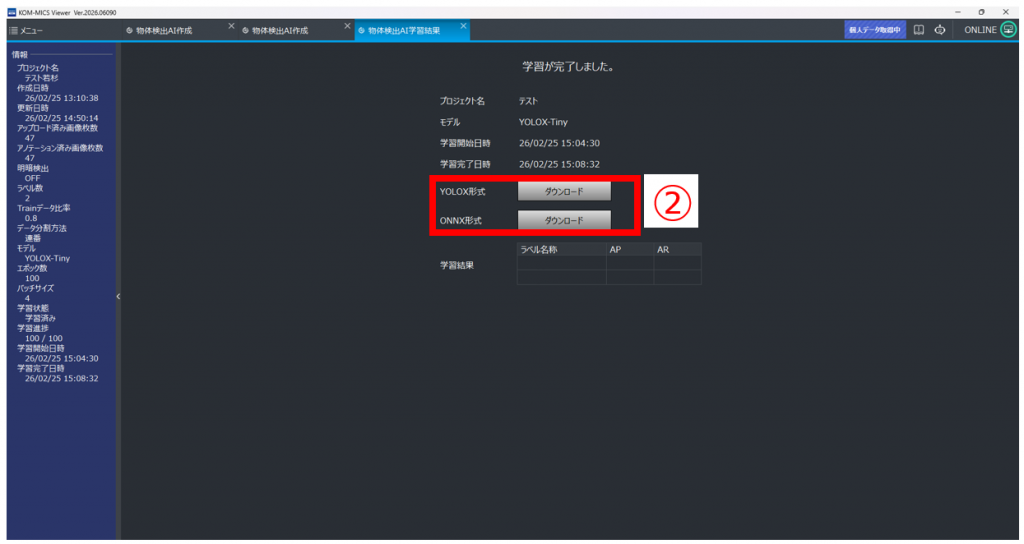
①「学習結果」をクリックし、学習結果画面を開く
②「ダウンロード」をクリックし、学習モデルを任意の場所に保存する
※Loggerに実装可能なファイルは、「ONNX形式」
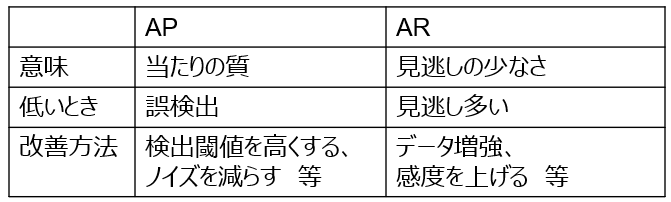
※精度指標の「AP・AR」について
AP:モデルが検出したもののうち正解だった割合を、複数の判定閾値で平均したもの
AR:実際の正解を、モデルも正解とした割合を、複数の判定閾値で平均したもの
指標の目安:
~0.3…精度低、0.3~0.5…精度中。検出対象によっては問題なく検出できる、0.5~…精度高。
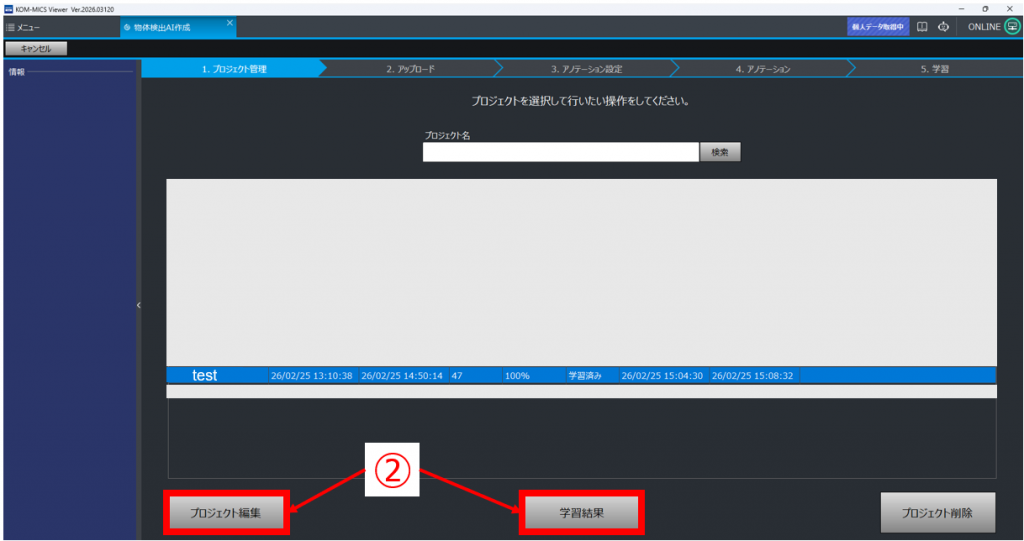
中断したプロジェクトの再開 #
①「プロジェクト管理」から、対象のプロジェクトを選択する
②作業再開したい場合は「プロジェクト編集」、学習結果を閲覧したい場合は「学習結果」をクリックする
補足 #
明暗検出機能
明暗検出機能は『「無いから0個」と「暗くて見えないから0個」を区別することができる』ものです。
例)
ラインの部品数をカウントする
条件:ラインが動いていない(照明がついていない)かつ、個数が0
判定:判定結果は信用しない
この機能を使う場合は、「明暗検出タグを用意し、タグもアノテーションする」必要があります。
明暗検出タグ設置の条件は以下のとおりです。
<タグ設置条件>
・常にカメラ映像に映る(遮られることがない)
・移動することがない
・照明が明るいときは鮮明に見え、暗いときは見えにくくなる